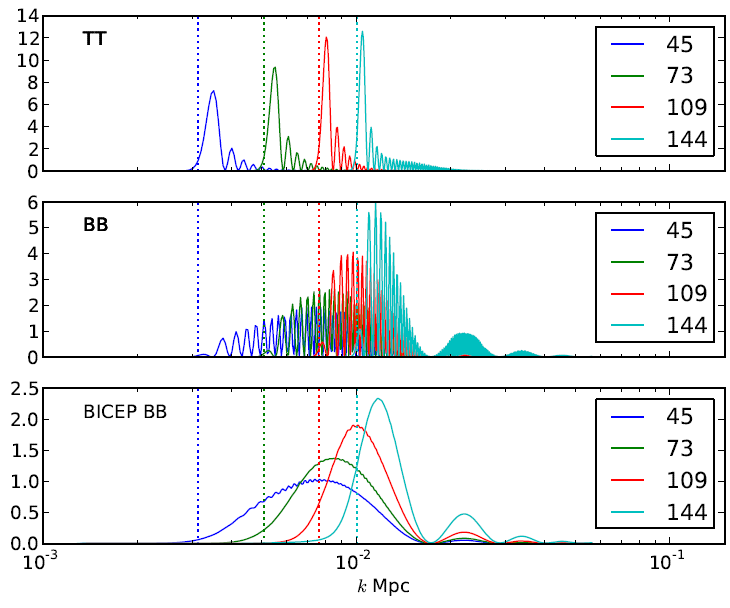
The high-looking points at [tex]l > 150[/tex] are obviously a concern: without using Keck array data the shape of expected primordial tensor B spectrum is not there. Taken at face value (which the authors warn against) it seems to favour a lot more power on sub-horizon scales than you'd expect from either primordial tensors or lensing. Combined with Planck's preference for a low TT plateau, which disfavours a large tensor amplitude on large scales, a naive application of the Planck+WP+BICEP likelihood to LCDM+[tex]r[/tex]+[tex]n_T[/tex] seems to favour a very non-inflationary [tex]n_T>0[/tex]:

Of course this should not be taken too seriously, since the Keck cross-correlation (their Fig 9) does seem to indicate something more like the expected shape at higher [tex]l[/tex]s, increasing overall confidence in the result and interpretation. The Keck points look systematically lower, which might indicate ultimately something closer to [tex]r\approx 0.16[/tex], and consistent with near scale-invariance. Hopefully more data from Keck will pin this down one way or another in relatively short order.
Even if you assume an inflationary consistency relation for [tex]n_T[/tex] so that it is nearly scale-invariant, the paper points out that the combination with the preference for low power on large scales in Planck then drives a preference for significantly lower scalar power on large scales than you'd expect from a nearly constant [tex]n_s[/tex] vanilla LCDM model. For example allowing running Planck+WP+BICEP gives [tex]n_{run}\approx -0.03\pm 0.02[/tex] (95%):
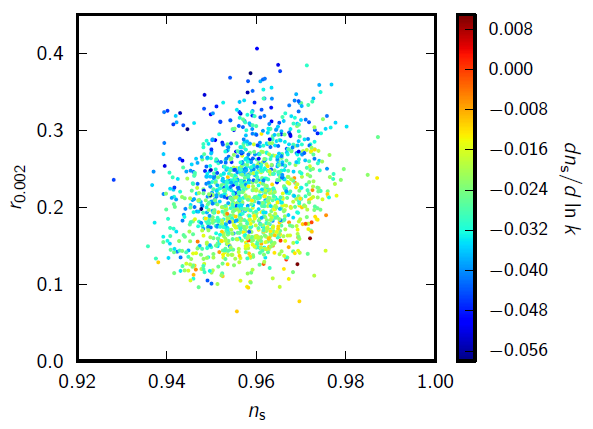
Of course anything else that can lower the large-scale scalar TT can also help to improve consistency, for example a sterile neutrinos allows for bluer [tex]n_s[/tex] and hence lower large-scale scalar power:

([tex]N_{eff}\approx 4[/tex] gives roughly scale invariant [tex]n_s[/tex] and fits about as well as running, though it is hard to motivate an extra sterile neutrino that thermalized at about the same temperature as the active neutrinos, and it is unlikely to improve joint fits on its own)
I look forward to seeing papers on inflationary transients that only strongly affect large scales (e.g. from bubble nucleation, fast-roll, etc) very shortly...
Please note above plots are just a preliminary quick-look and come with usual health warnings.